-
[Anomaly Detection] Isolation ForestLearn/머신러닝 2022. 8. 11. 13:52
# 개요
- 모델 기반 이상치 탐지 알고리즘 중 하나
- 이 모델은 분류를 한다기보단 Score가 나옴.
# 기본 개념
- Decision Tree와 마찬가지로 y를 균일하게 분류하는게 목표
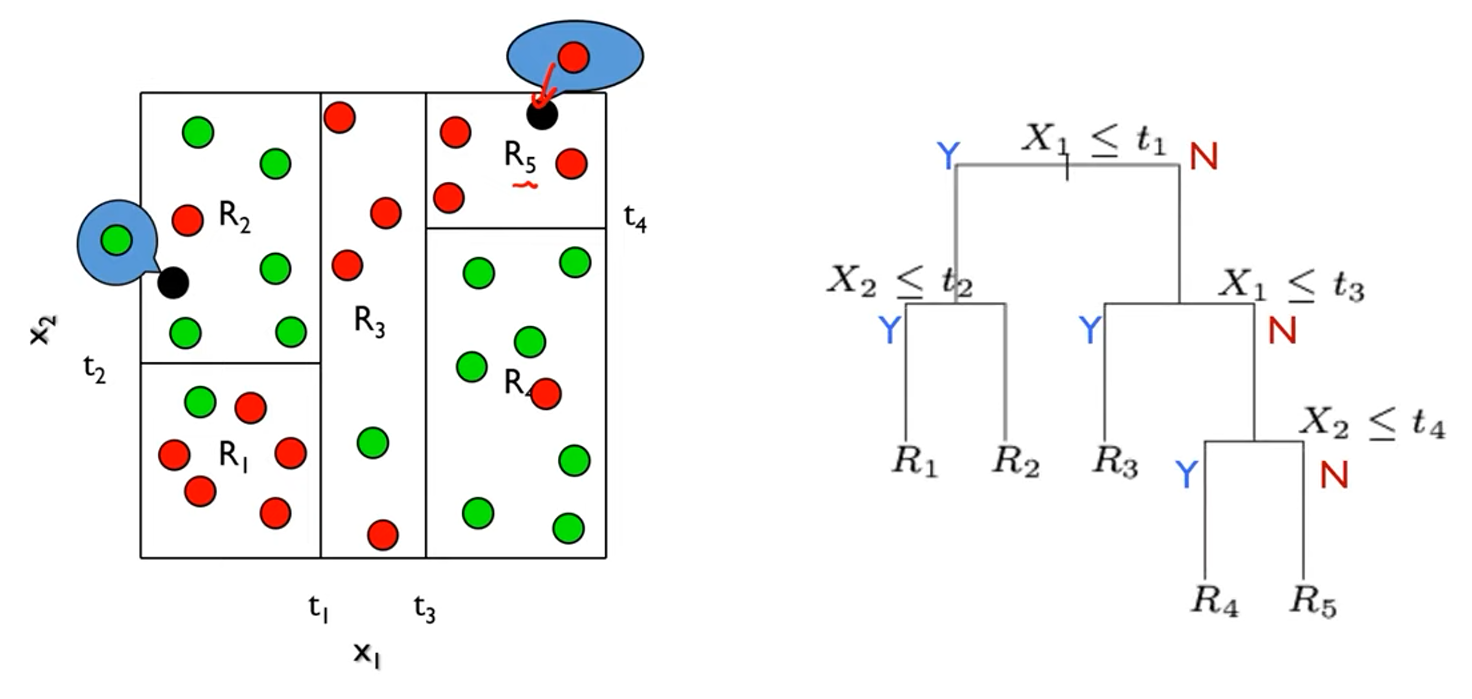
- 아래 그림은 t1 > t2 > t3 > t4 순으로 나눴음
> x1, x2간의 분할 순서, t를 어디로 잡을 것인지가 중요

- 모델 구실을 하려면 미래 데이터를 예측할 수 있어야 함
> 어떤 구역에 미래 데이터가 속했는지를 보고 다수(majority)를 따르면 됨
- Decision Tree로 표현하면 오른쪽과 같음
> 마지막 노드를 Terminal node라고 부르며 이게 중요
- Full-Grown Tree를 만들경우 overfitting
# 분할점은 어떻게 정할까?
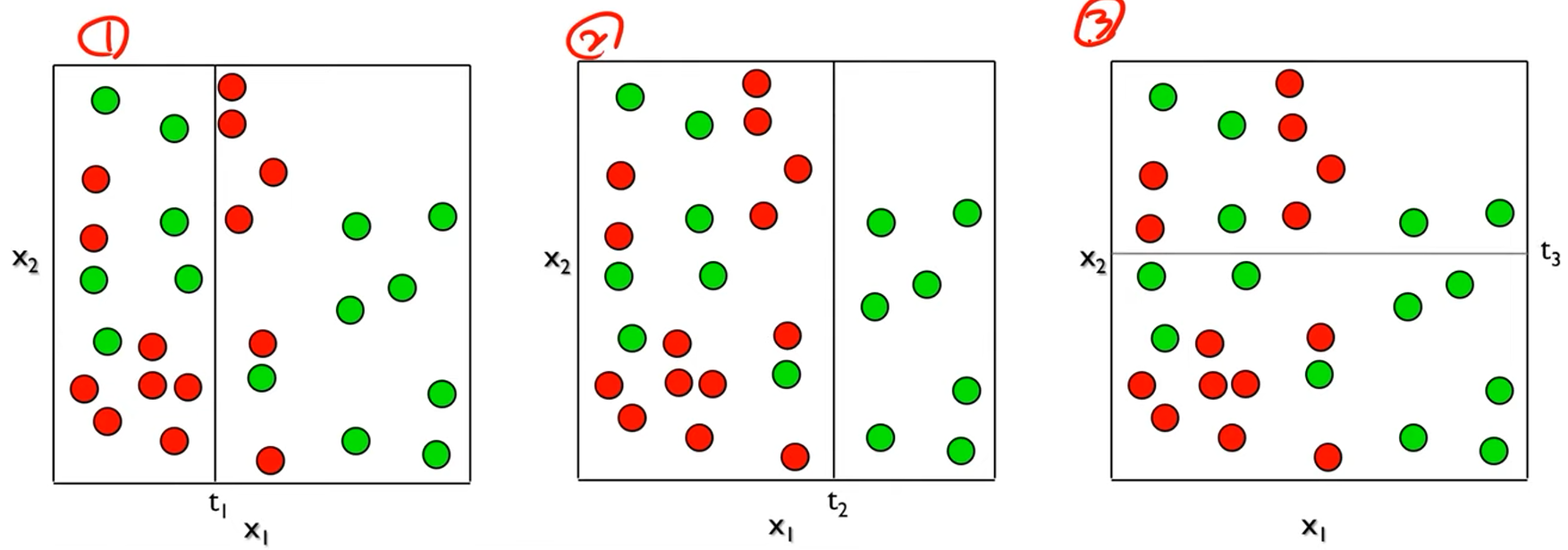
위 그림에서 몇 번이 가장 잘 나눈 것일까?
> 두 번째 그림은 초록색이 잘 나뉘었다.
> 엔트로피가 작다
엔트로피를 최소화하는 방향으로 분할점을 정한다.
> 하나씩 다 계산해봐야한다. (greedy search)
# Regression 문제는 어떻게?
분류와 컨셉은 같은데 majority vote대신 평균을 사용해볼 수 있다. (또는 max, median 등)
아래의 경우 R1~R5 Terminal node에는 y의 평균값이 들어간다.

수식으로 표현하면 아래와 같은데, 어렵게 생각할 필요가 없다.
각각의 I는 Ture면 1, False이면 0을 가질 것이므로, 새로운 예측 값에 대해서 하나의 c값만 남는다.
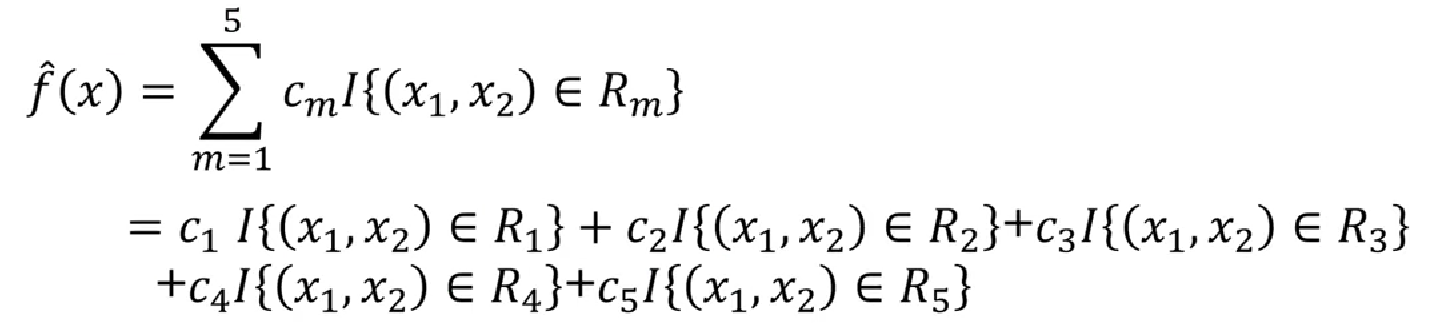
Regression에서는 엔트로피를 사용할 필요가 없다.
> MSE가 최소가 되는 분할점을 찾는다.
# Isolation Forest
한 객체를 고립시키는 의사결정나무 모델을 구축하는 방법론
정상 관측치는 고립시키기 위해 많은 분리 횟수 필요
불량 관측치는 고립시키기 위해 적은 분리 횟수 필요
> 분리 횟수를 path length라고 함

path lenght = 6 vs path length = 2 # 어떻게 분할할 것인가?
y변수(레이블 정보) 없이 어떻게 모델을 구축할까?
> 전체 데이터에서 일부 관측치를 랜덤하게 선택
> 분할변수와 분할점도 랜덤으로 설정해서 분할 진행
> 모든 터미널 노드에 관측치가 1개일때까지 진행 (Full Grown Tree)
# Anomaly Score
path length를 기반으로 anomaly score 정의 (normalized)
> path length: x가 고립될 때 까지 필요한 분할 횟수

E(h(x)): 내가 관심있는 관측치의 평균 path length
c(n) : 모든 관측치의 평균 path length (normalize를 위해 사용)
> 다 직접 구해야되는건 아니고 오일러 상수를 이용해서 구할 수 있다고 함
E(h(x)) → 0 s(n, x) → 1 path length 평균이 0에 가까우니 이상 데이터 E(h(x)) → n-1(큰 값) s(n, x) → 0 path length 평균이 n에 가까우니 정상 데이터 E(h(x)) → c(n) s(x, n) → 0.5 path length 평균이 c(n)과 비슷하니 정상 데이터 1에 가까우면 이상, 0.5이하면 정상 같은 방식으로 볼 수 있음 (0~1사이 값으로 normalize)
0.6같은건..? 좀 애매한다.
'Learn > 머신러닝' 카테고리의 다른 글
[Anomaly Detection] PCA, Autoencoder, GAN (0) 2022.08.12 [Anomaly Detection] SVM, SVDD (1) 2022.08.11 [Anomaly Detection] Local Outlier Factor (LOF) (0) 2022.08.10 [Anomaly Detection] 개요, 확률 분포 기반 (0) 2022.08.10 Pandas 2부 (0) 2021.05.26