-
[Anomaly Detection] 개요, 확률 분포 기반Learn/머신러닝 2022. 8. 10. 13:10
# Novelty vs Anomaly vs Outlier
비슷한 듯 하지만 다르다. 그런데 우리나라에서는 다 '이상치'로 번역.
Novelty
- 본질은 같지만 특성이 같은 유형
ex. 일반 호랑이가 정상 데이터일 때 백호는 novelty
Anomaly
- 대부분의 데이터와 특성이 다른 관측치.
- 약간 부정적인 느낌이 있음.
ex. 일반 호랑이가 정상 데이터면 라이거는 anomaly
Outlier
- 대부분의 데이터와 본질적인 특성이 다른 관측치.
- 아주 부정적인 느낌. 보통 데이터에서 발견되면 삭제함.
ex. 일반 호랑이가 정상 데이터면 사자가 outlier
# Anomaly Detection
이상치는 정상 데이터보다 소수 (심한 불균형)
> Classification이 잘 되지 않는다!
classification이지만 class를 이용하지 않기 때문에 보통 one-class classification 이라고 부른다.

정상 데이터를 잘 아우르는 바운더리를 찾아야 함
> 너무 크지도 않게, 너무 타이트하지도 않게
# 언제 사용할 것인가?
- 정상 데이터만 있는 경우 (평가는 어려움)
> 현재 이상치가 없다고 포기하지말고 모델링하자. 나중에 나올 수도 있다.
- 이상치 데이터가 극소수인 경우
# 이슈
- 정상 데이터를 정의하기 어려운 경우
- 어떤 종류의 이상치인지 모르는 경우 (이상치의 종류가 많음)
> 별도의 사후 분석이 필요 (post-hoc analysis)
# 밀도 기반 Anomaly Detection 알고리즘
알고리즘이 되려면 객관적인 score과 threshold가 필요하다.
확률분포로 접근할 수 있다.
> 단, 데이터가 우리가 알고있는 분포인건 현실적이지 않다.
(그렇지만 여기서 확장되는거니 알아야한다)

# Gaussian Density Estimation
- 각 객체가 생성될 확률을 하나의 정규분포로 가정
- 정상 관측치는 높은 확률, 불량 관측치는 낮은 확률을 가진다는 가정


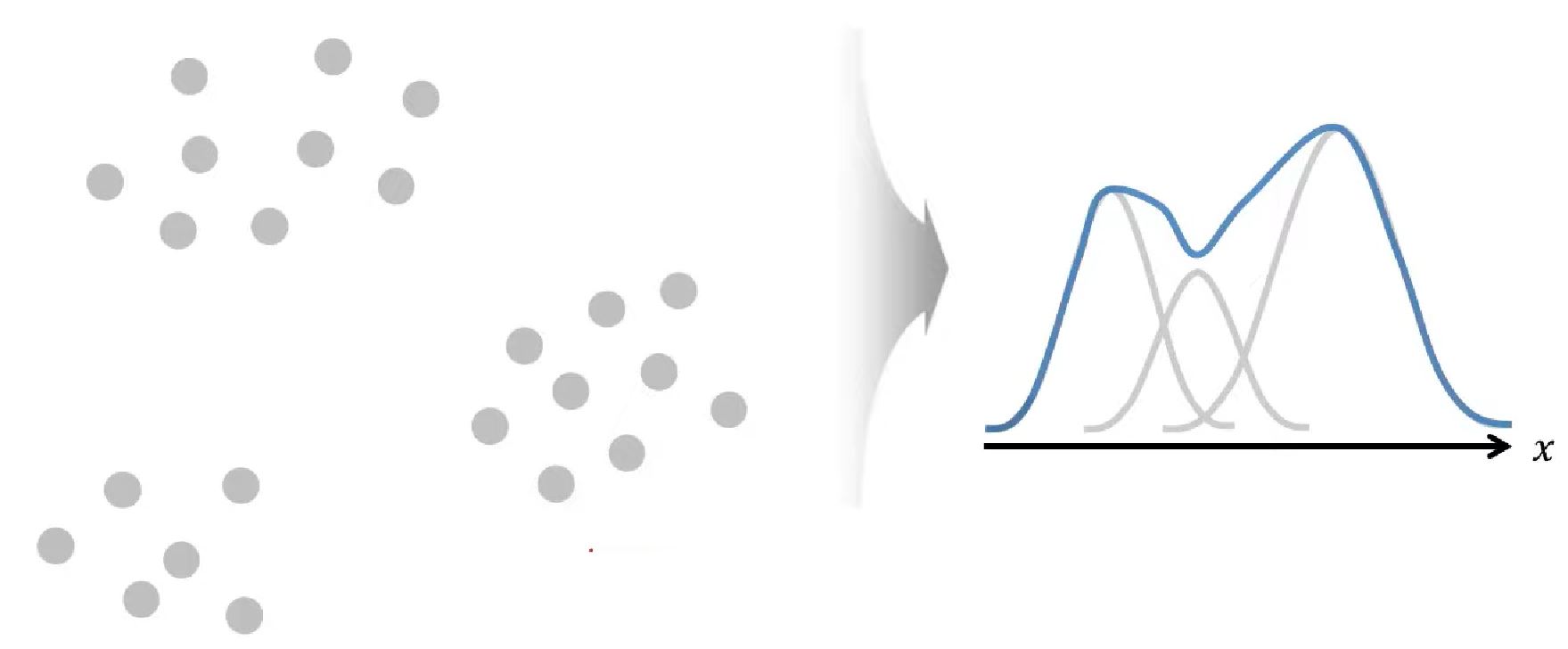
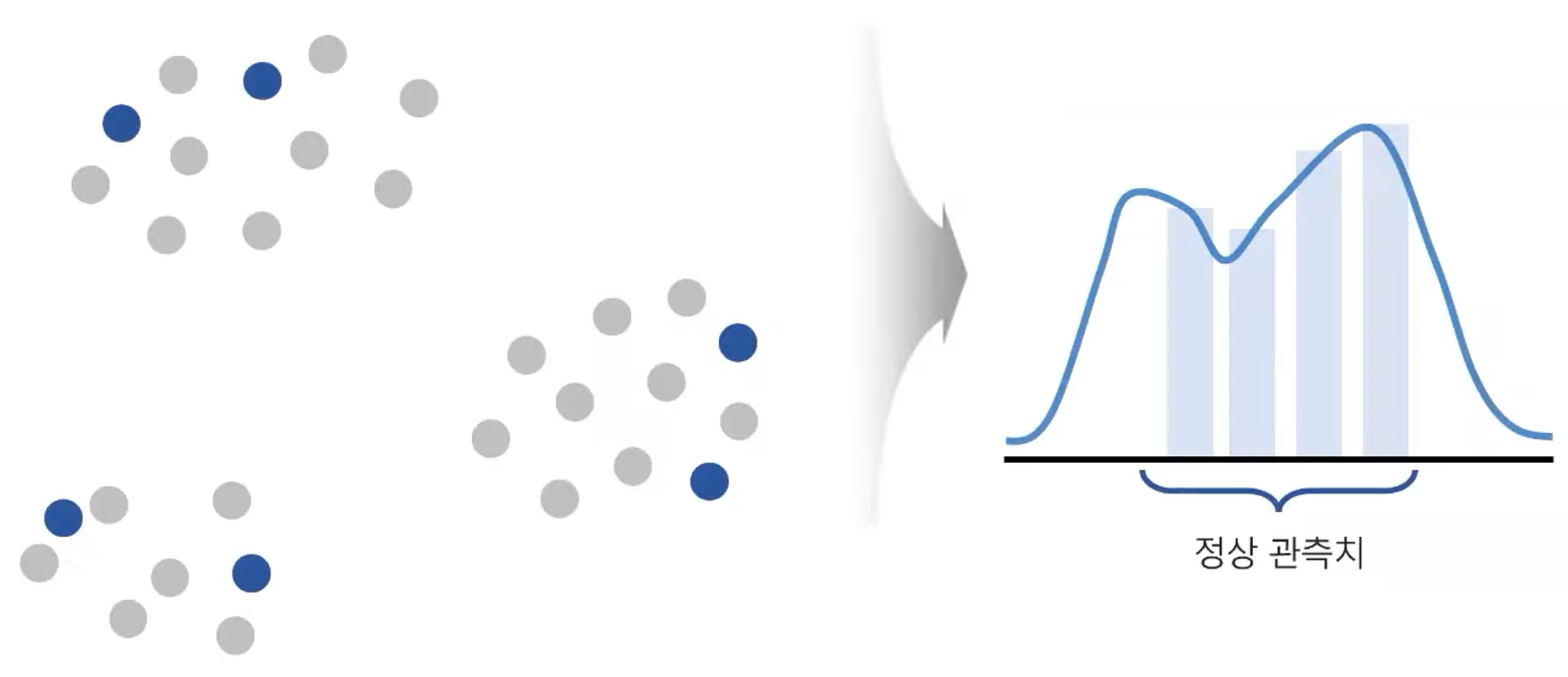
# Mixture of Gaussian Density Estimation
- 각 객체가 생성될 확률을 여러 정규분포의 선형 결합으로 가정하는 방법론
- 가운데 골짜기는 세 클러스터 사이의 빈 공간인데 이상치일 수도 있고 정상일 수도 있다.

# Local Outlier Factor (LOF)
- 각각의 지점에 대한 score를 구하는 알고리즘
- 단, threshold는 제시하지 않음

LOF는 각 지점마다 스코어가 있다. LOF는 뒤에서 다시 자세히 정리
강의 영상, 그림 출처: https://youtu.be/TqSwuCX7Lds
'Learn > 머신러닝' 카테고리의 다른 글
[Anomaly Detection] Isolation Forest (0) 2022.08.11 [Anomaly Detection] Local Outlier Factor (LOF) (0) 2022.08.10 Pandas 2부 (0) 2021.05.26 Pandas 1부 (0) 2021.05.25 ndarray (0) 2021.05.07