-
[Anomaly Detection] Local Outlier Factor (LOF)Learn/머신러닝 2022. 8. 10. 17:17
# 개요
- 한 객체 주변 데이터 밀도를 고려한 이상치 탐지 알고리즘
- 정상 객체는 주변에 데이터가 많이 존재하고, 불량 객체는 단독으로 존재한다는 가정
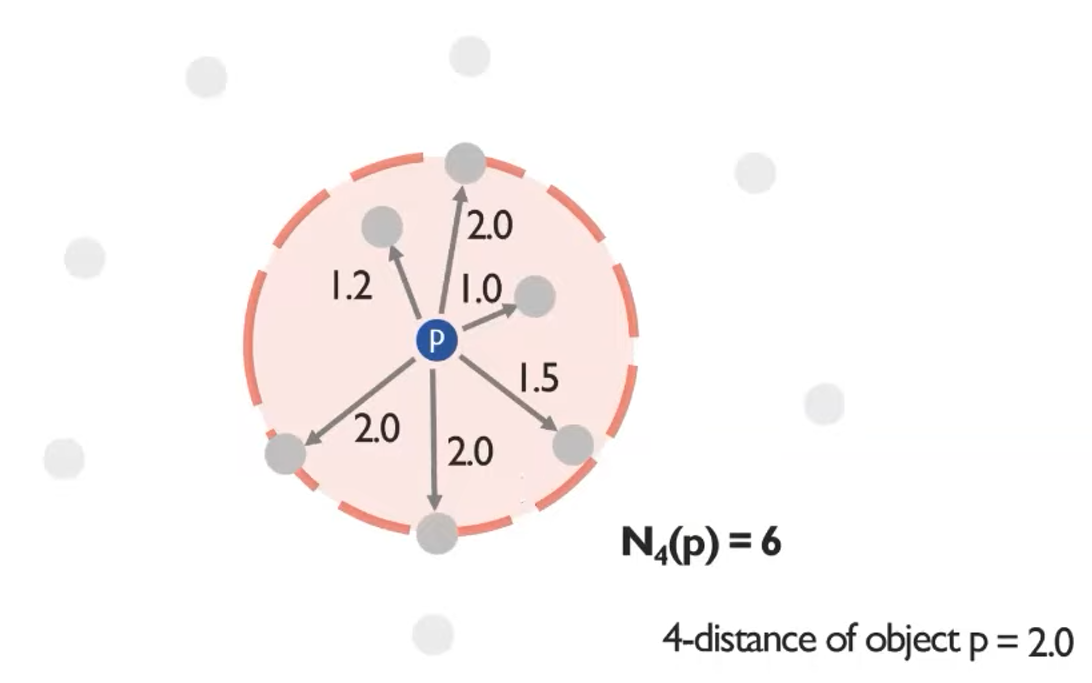
1. K-distance of object p
- 자기 자신(p)을 제외하고 k번째로 가까운 이웃과의 거리

2. K-distance neighborhood of object p(Nk(p))
- k번째로 가까운 이웃과의 거리를 원으로 표현할 때, 원 안에 포함되는 모든 객체들의 개수
- 커트라인에 걸린 동률인 것도 다 포함된다.
- 실제 계산때는 모든 점에 대해 거리를 다 구하고 sorting이 필요하다.
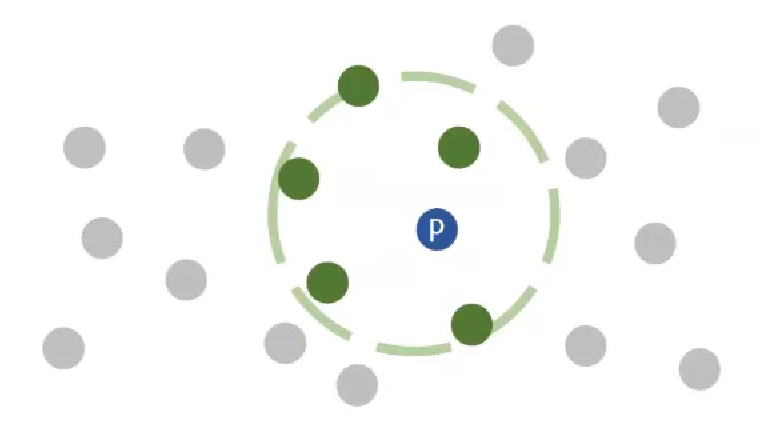
3. reachability Distance (Reachability distance_k(p, o))
- ①o를 기준으로 k번째 가까운 이웃과의 거리(k-distance of o)와 ②o와 p사이 거리 간의 최대 값
- p기준이 아니라 o기준임에 유의
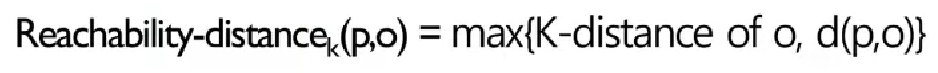

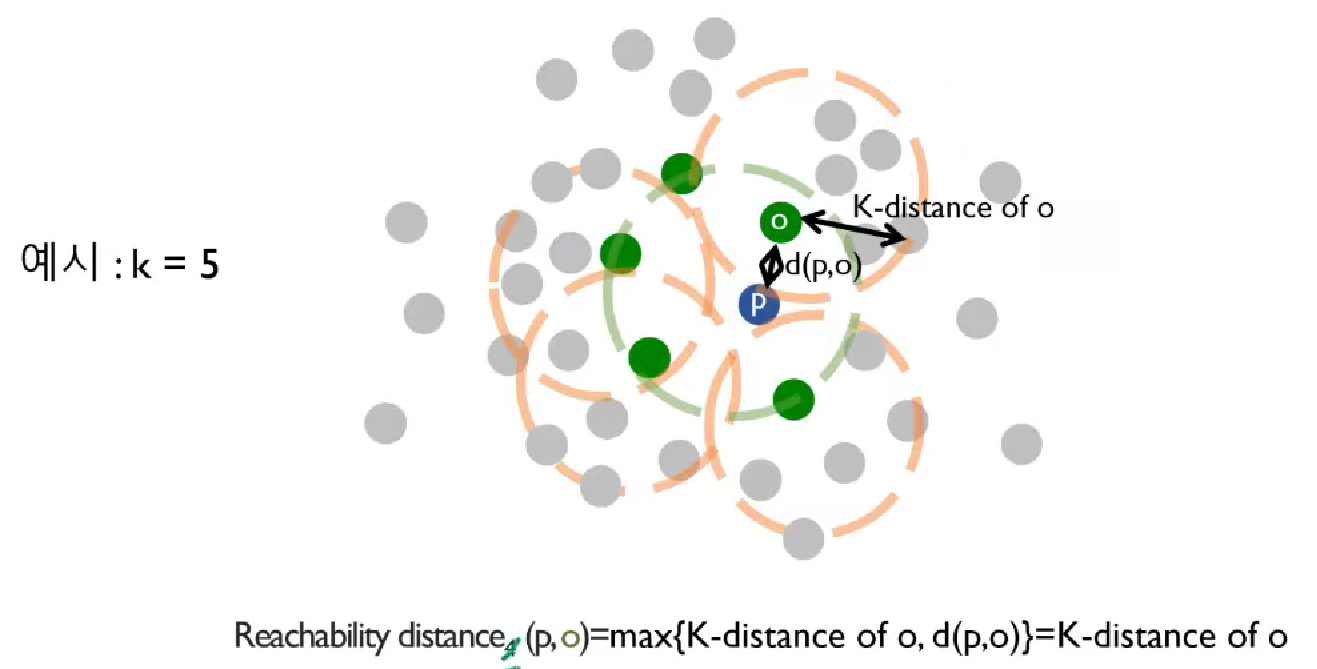
아래와 같이 둘 다 이상치가 아닐 경우 d(p, o)에 비해 K-distance of o가 그리 크지 않고 둘 다 짧다.
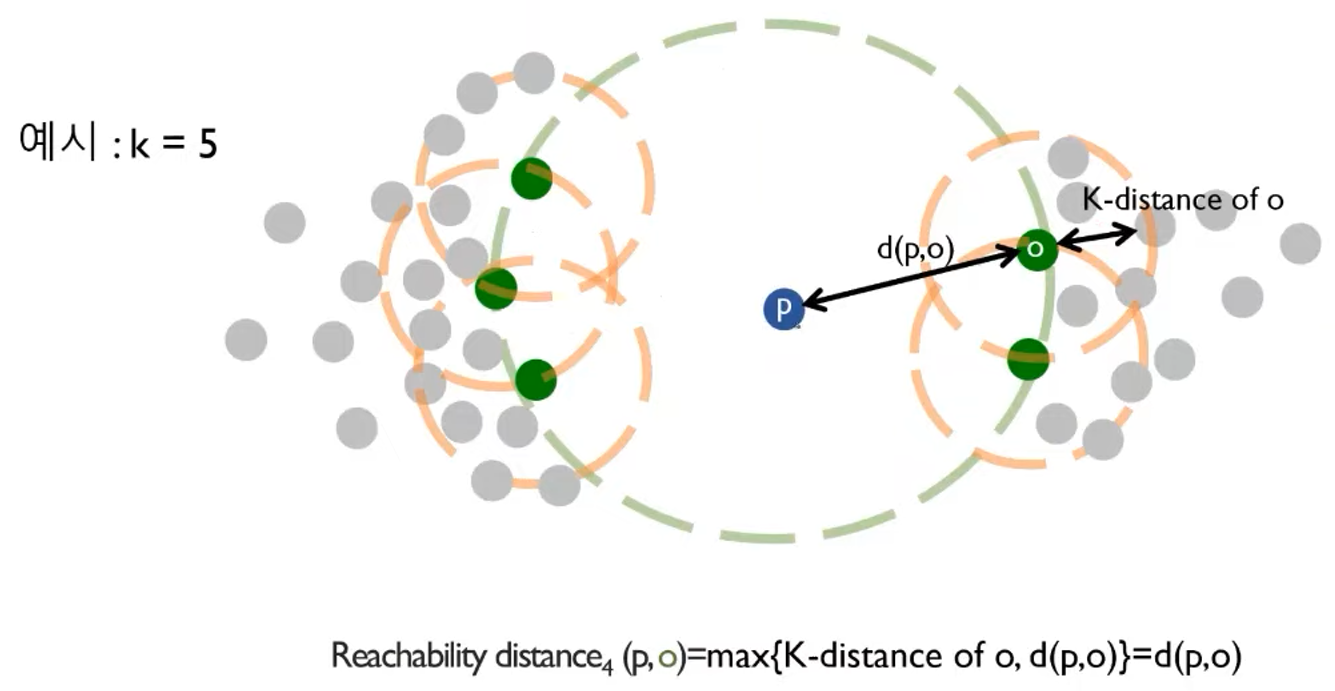
아래와 같이 p가 이상치일 경우 d(p, o)가 K-distance of o에 비해 매우 크다.
4. Local reachability density of object p(lrd_k(p))
- 여러 reachability distance를 하나의 지표로 계산한 값
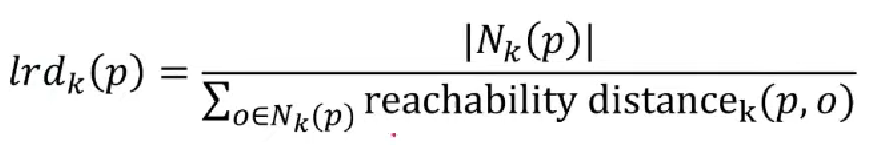
> 분자: 2번에서 구한 것, 분모: 3번에서 구한 것
> 원 안에 들어간 점이 많을 수록 분자가 커짐
> 밀도가 높으면 분모가 작아짐 --> lrd 값은 커짐 --> 정상
5. Local Outlier Factor of object p (lrd_k(p))
- 자기 자신(p)의 최종 Local Outlier Factor 값을 계산
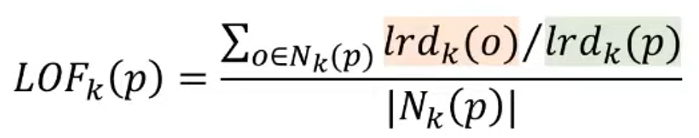
Case 1. 정상 데이터이고 모여있음
p, o 주변 밀도 모두 높음 >> lrd_k(o), lrd_k(p) 모두 큼 >> 1근방의 LOF
p주변 밀도 높음 >> lrd(p) 큼 
o주변 밀도 높음 >> lrd(o) 큼 Case 2. 이상치라서 떨어져있음
p 주변 밀도는 낮고, o 주변 밀도는 높음 >> lrd_k(p)는 작고 lrd_k(p)가 큼 >> 큰 LOF (1보다 큼)

p주변 밀도 낮음 >> lrd(p) 작음 
o주변 밀도 높음 >> lrd(o) 큼 Case 3. 정상 데이터인데 다소 듬성듬성함
p, o 주변 밀도 둘 다 낮음 >> 작은 lrd_k(p), lrd_k(o) >> 1근방의 LOF
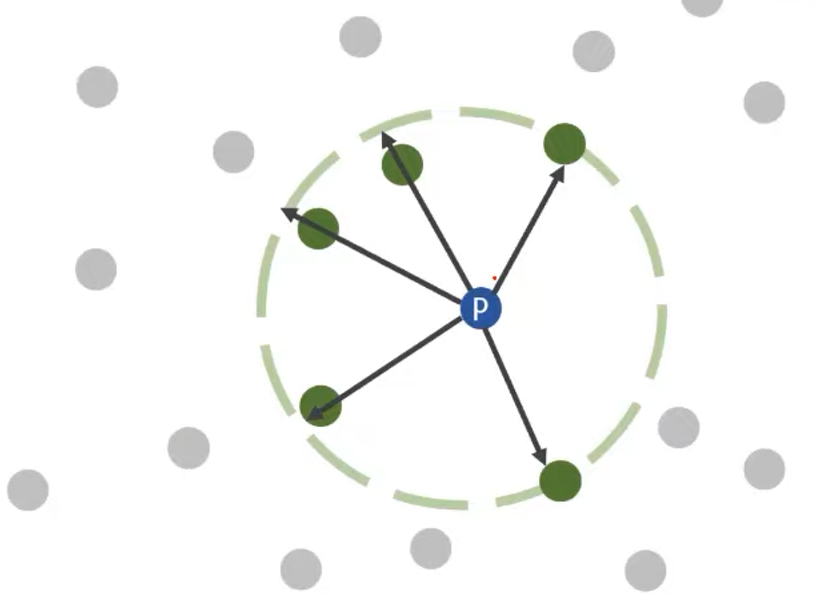
p주변 밀도 낮음 >> lrd(p) 작음 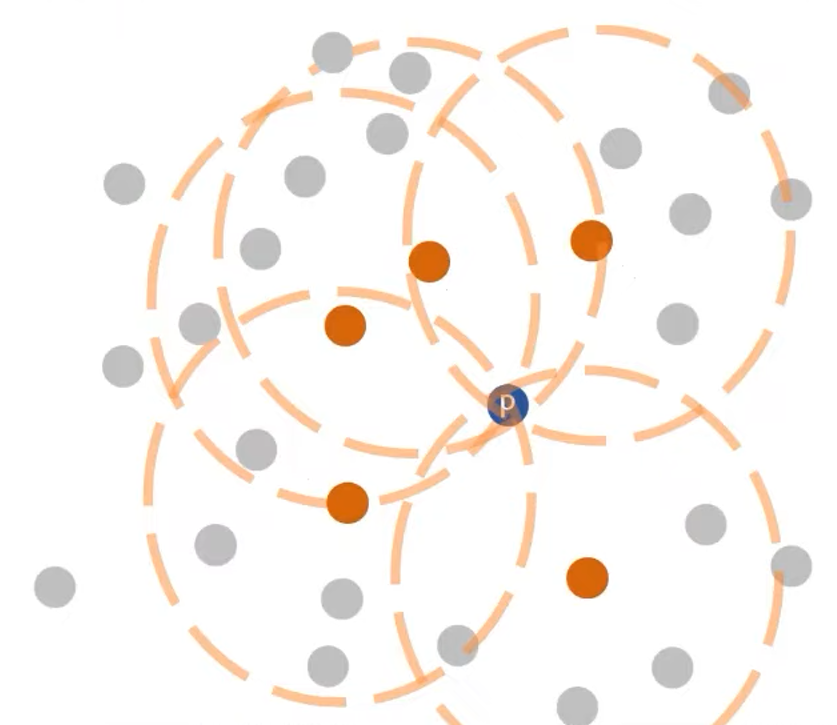
o주변의 밀도 낮음 >> lrd(o) 작음 
- 정상 데이터들은 1점대의 스코어를 가짐.
- 위 그림에서 2점대 포인트들은 정상 데이터와 비슷한데 다소 LOF가 큼
>> 밀집된 군집 옆에서는 조금만 떨어져도 LOF가 높게 나옴
# 이슈 (생각해볼 것)
- K를 어떤 값으로 정할까?
>> 크게 민감하지 않으면 좋다. (Robustness)
- LOF가 어떤 값 보다 커야 anomaly로 정의할까? (thresholding)
>> 이상치를 몇 개 찾을지 정하는 방법도 있음
- 서로 다른 데이터셋에서 각각 2.1의 LOF값을 가지는 관측치들은 모두 동일하게 anomaly인가? (또는 정상인가?)
- 계산복잡도
>> k-NN같이 거리를 구해야하는 알고리즘은 거리를 다 구하고 sorting도 해야하므로 복잡도가 크다.
- 고차원
>> 고차원에서는 LOF가 잘 안맞다.
>> 차원축소 활용
'Learn > 머신러닝' 카테고리의 다른 글
[Anomaly Detection] SVM, SVDD (1) 2022.08.11 [Anomaly Detection] Isolation Forest (0) 2022.08.11 [Anomaly Detection] 개요, 확률 분포 기반 (0) 2022.08.10 Pandas 2부 (0) 2021.05.26 Pandas 1부 (0) 2021.05.25