-
[Anomaly Detection] PCA, Autoencoder, GANLearn/머신러닝 2022. 8. 12. 15:26
# 재구축 오차
원본 데이터를 압축했다가 다시 원본과 같은 차원으로 복원하는 과정을 거침.

복원력이 좋다면 X는 X'과 거의 같을 것이다.
> 원본 데이터와 복원된 데이터의 차이를 통하여 재구축 오차(reconstruction error) 계산
# 재구축 오차 기반 이상치 탐지 알고리즘
- 이상 관측치(anomaly)들은 잘 복원되지 않을 것이라는 가정으로 접근
- 잘 복원되지 않은, 즉 재구축 오차가 큰 관측치를 찾아 이상으로 정의
> 정상 데이터로 학습해야한다.
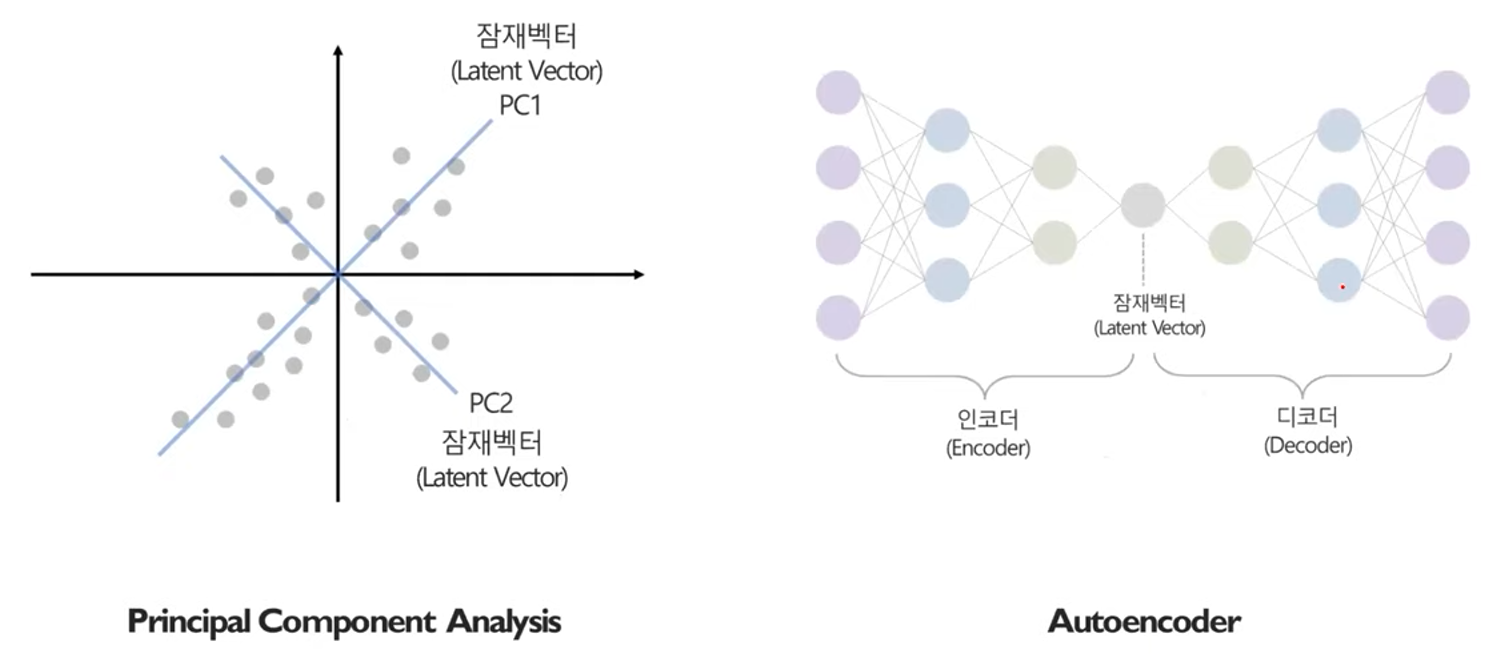
# Principal Component Analysis (PCA)
원본 데이터의 분산을 최대한 보존하는 새로운 축을 찾고, 그 축에 데이터를 projection 시키는 기법
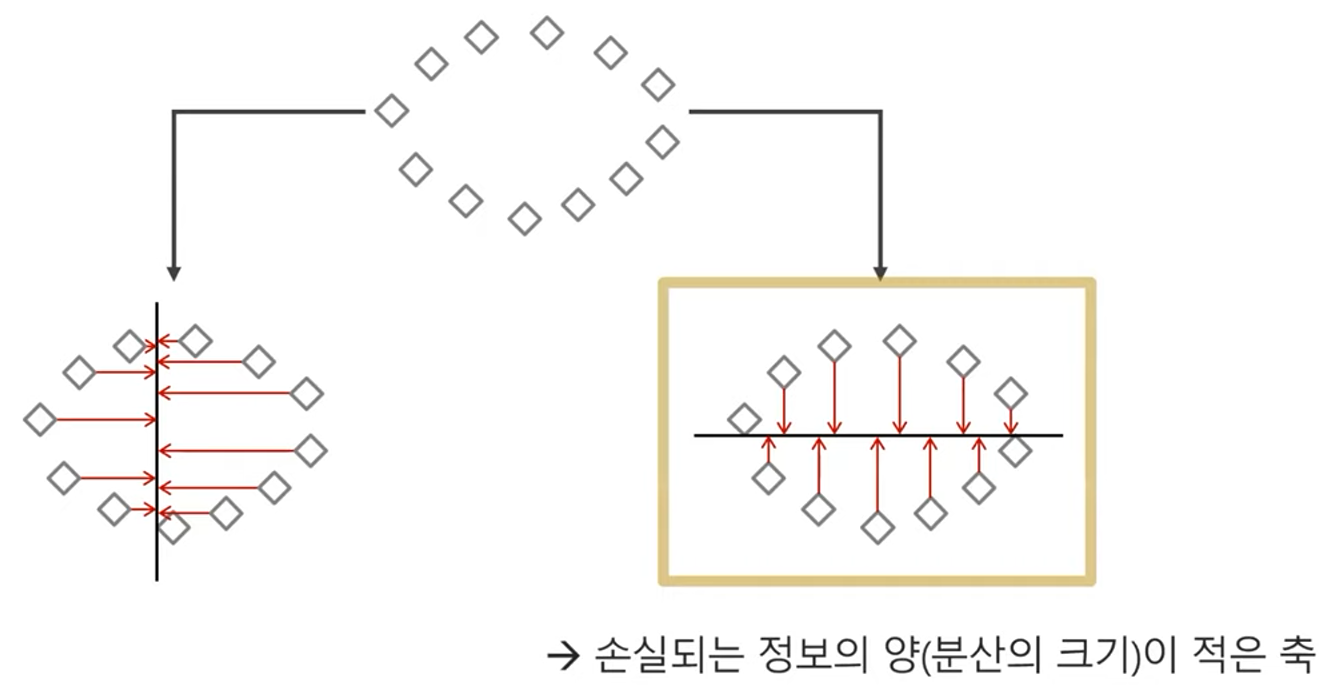
재구축된 데이터와 기존 데이터 사이의 차이를 재구축 오차로 정의

# Autoencoder
입력된 데이터의 특성을 요약하는 인코더와, 요약된 정보를 복원하는 디코더의 형태
Encoder, Decoder쪽 각각 neural network가 있다.

가정: 정상 관측치들은 불량 관측치보다 더 잘 복원될 것이다.
재구축 오차가 특정 임계값보다 크면 이상치로 판단
> thresholding은 평균으로부터 얼마나 떨어졌는지를 써도 되고 다른 방법도 많이 있다.
# LSTM-Autoencoder
- Sequence 데이터를 위한 LSTM 구조를 사용하는 autoencoder
*sequence: 이전 관측치와 현재 관측치 사이에 관계가 있는 모든 데이터를 뜻함
- Encoder, Decoder에 LSTM을 적용한 방식
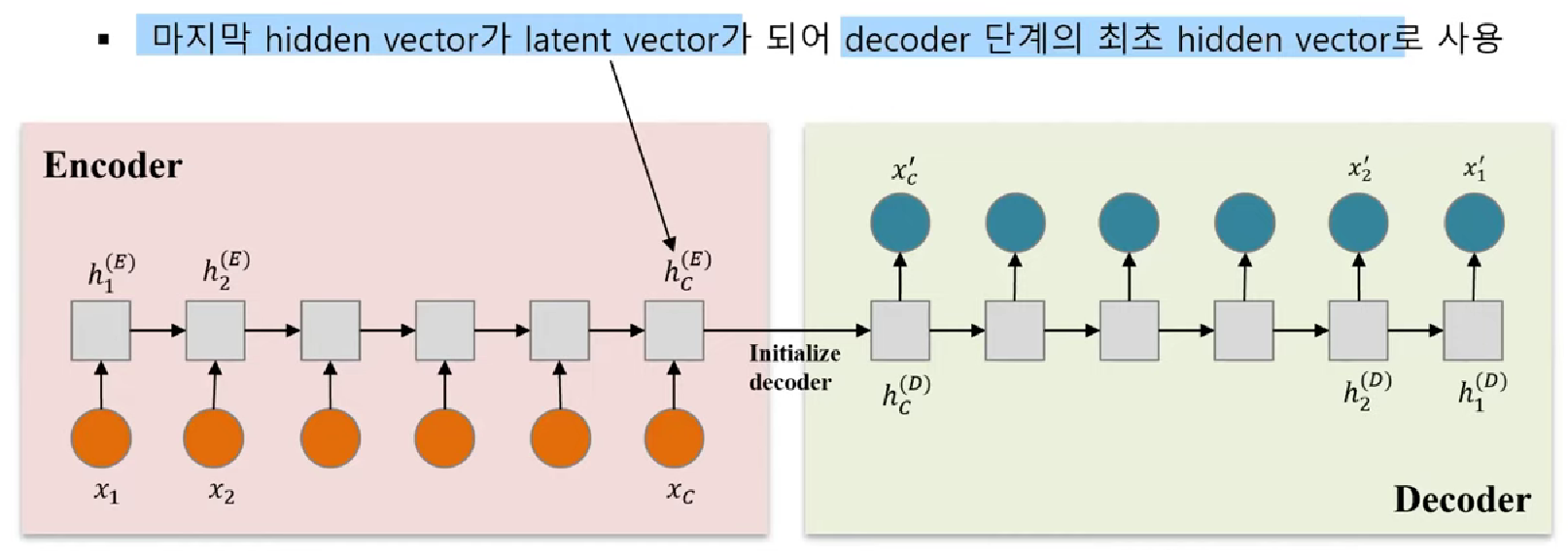
# EncDec-AD
- Training은 정상 데이터 사용
- hidden vector는 이전 단계의 hidden vector(h)와 입력값(x)을 활용

- Decoder의 복원은 Encoder 데이터의 역순으로 진행
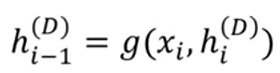
정상데이터로 error vector를 구해서 정규분포로 추론
> μ까지의 마할라노비스 거리를 계산해서 멀면 이상값으로 판단 (임계치 τ는 정해야함)
Autoencoder는 Convolutional, Variational, Adversarial 등 종류가 많다.
# Robust Deep Autoencoders
기존의 Robust PCA를 활용 (RPCA)
- 데이터를 최저 계수 행렬(low rank matrix)과 희소 행렬(sparse matrix)로 분할

Robust Deep Autoencoders는 RPCA에서 나온 깨끗한 데이터(low rank matrix)를 가지고 autoencoder하겠다는 것

# Generative Adversarial Network (GAN)
※ Adversarial(적대적인)은 크게 중요한 단어가 아님.
generator: 임의의 값으로부터 가짜 데이터를 생성
discriminator: 생성된 데이터와 원본 데이터를 구분
이상치 탐지가 목적이니 정상 데이터를 기반으로 학습 진행

이상치 탐지에 유명한 GAN은 AnoGAN과
# AnoGAN
심층 합성곱 GAN (DCGAN)을 기반으로 이상 이미지를 탐지 (CNN으로 대충 봐도됨)
정상 데이터에 특화된 Generator를 생성

잠시 기존의 Generator와 Discriminator의 학습은 멈춤.
그리고 랜덤 이미지로 학습 진행
> 정상 이미지의 잠재 공간을 찾는 단계 (how...?)

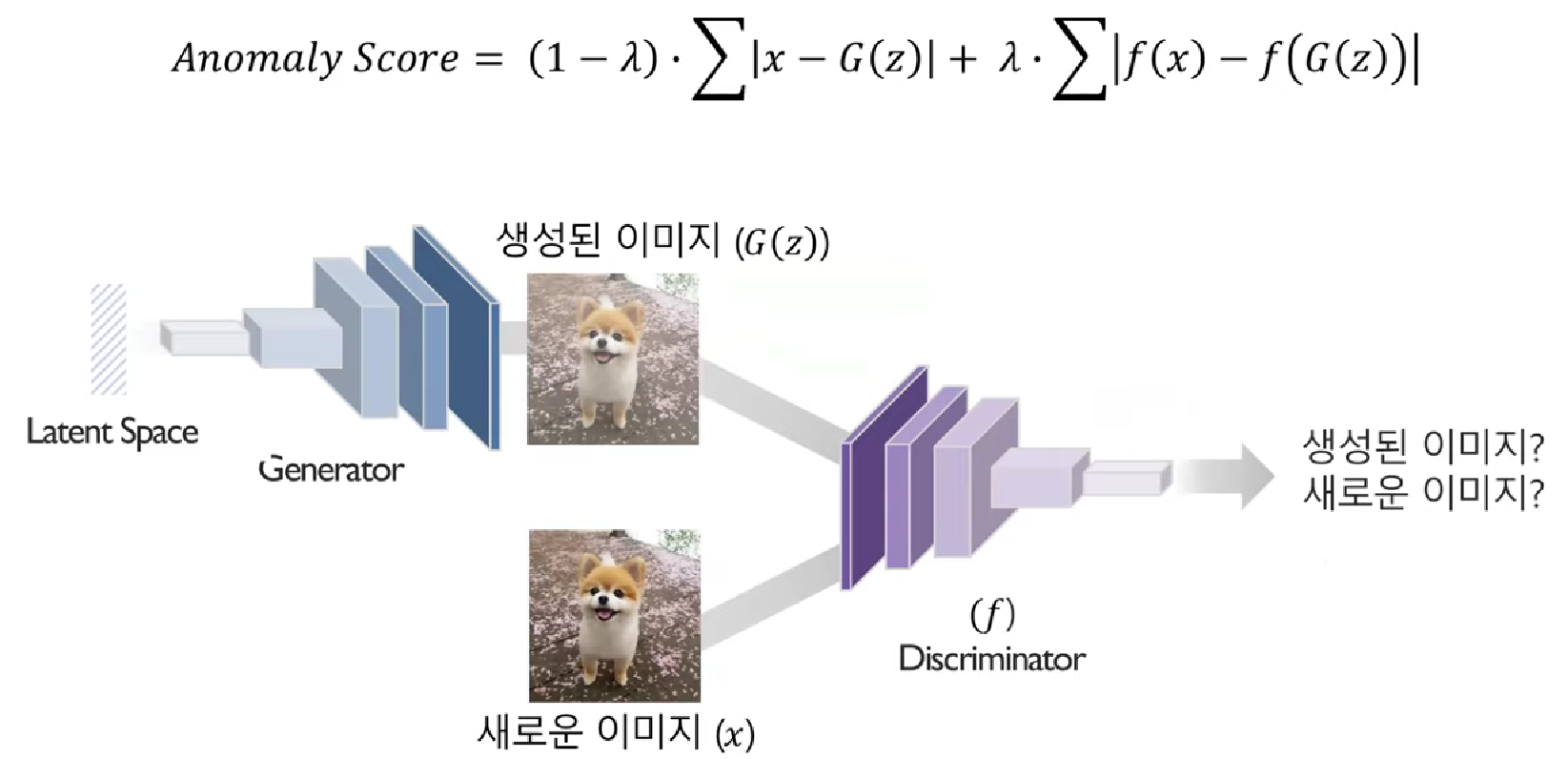
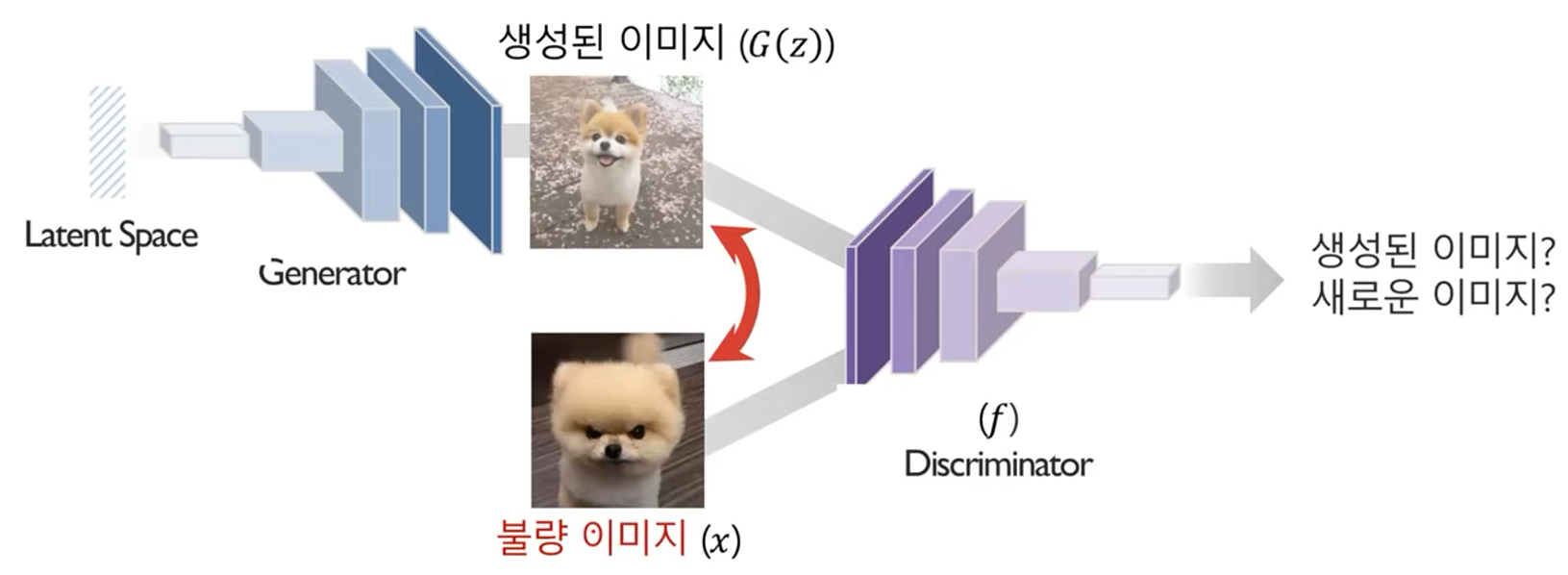
새로운 이미지로 이상치 점수를 계산
> 두 이미지의 점수 차이가 비슷하면 정상, 크면 비정상으로 간주
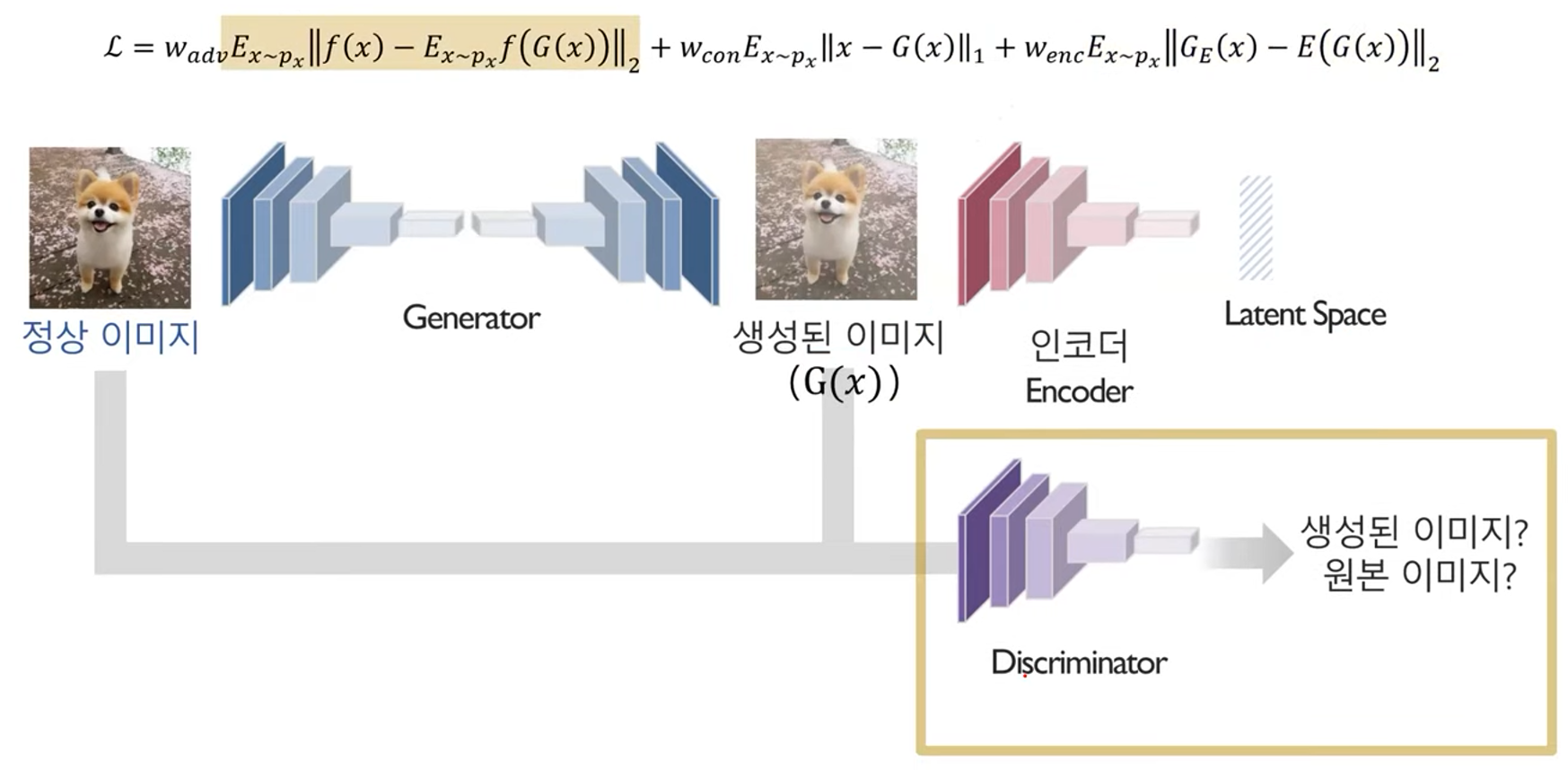
# GANomaly
두 단계로 이루어진 AnoGAN을 한 번에 진행하도록 제안된 방법론
1. 생성된 이미지가 정상 이미지의 특성을 잘 반영하도록 학습
(위의 식은 loss function)
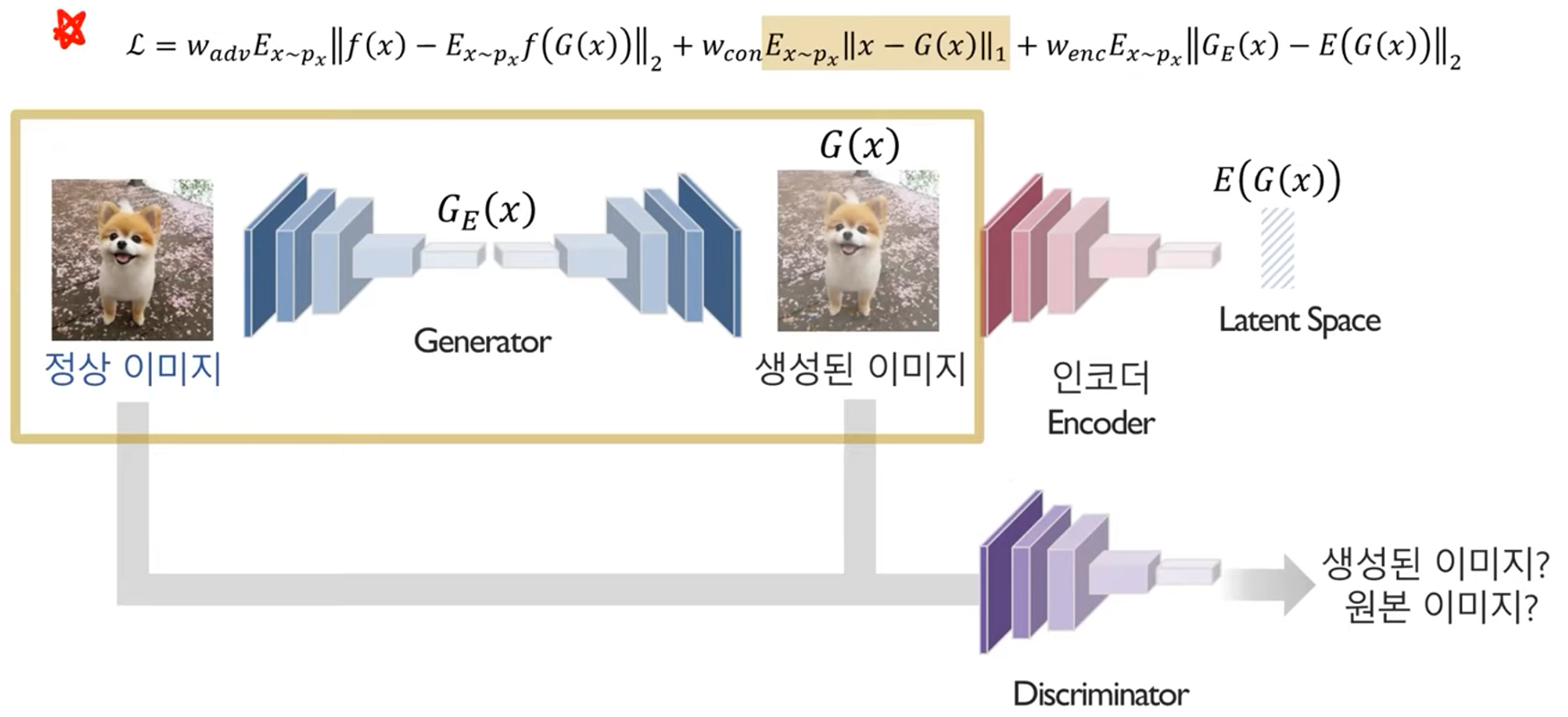
2. 정상 이미지의 요약된 특성과 생성된 이미지의 요약된 특성의 차이가 적도록 학습
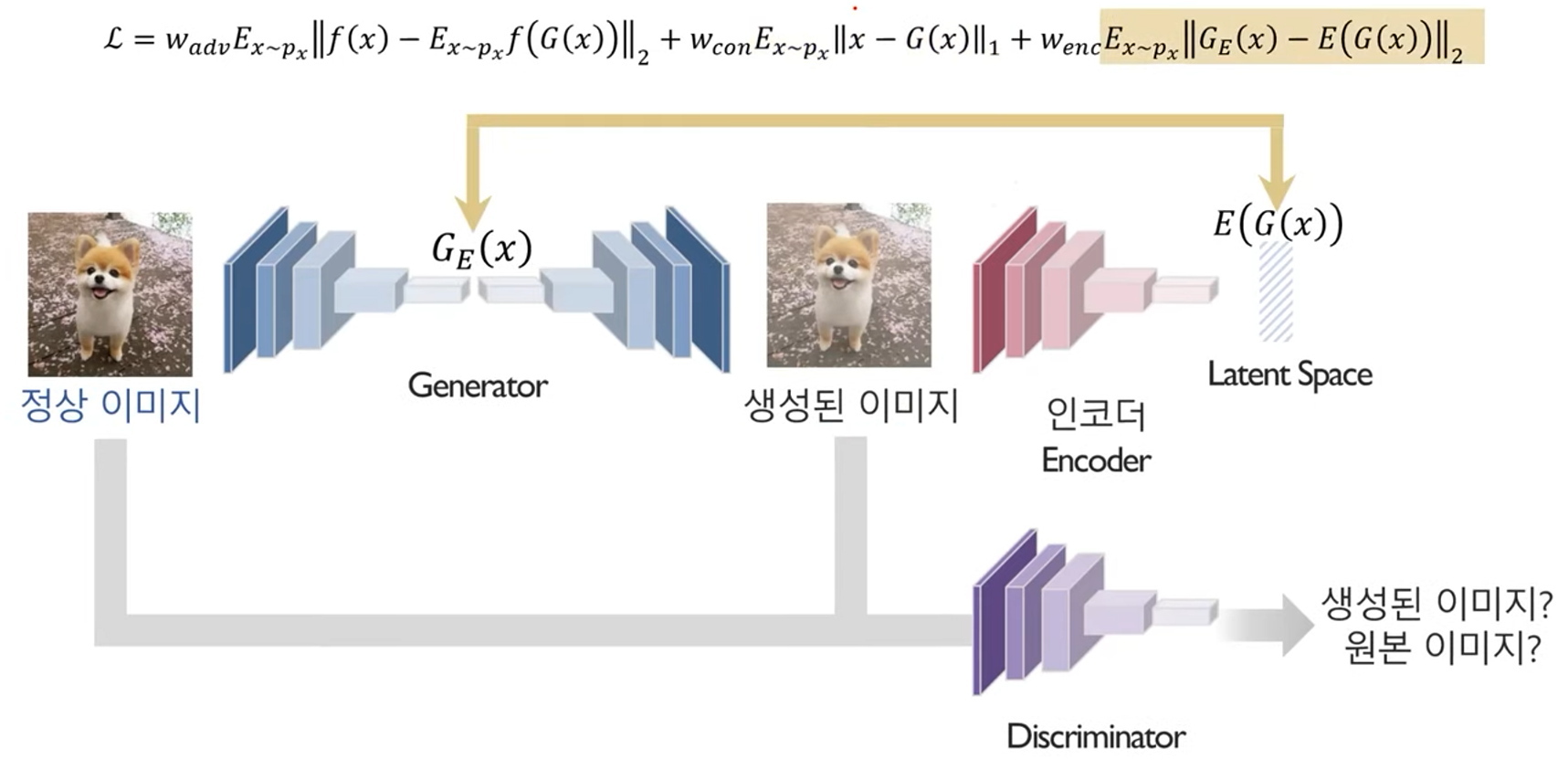
3. Discriminator 모델이 생성된 이미지와 원본 이미지를 잘 구분하지 못하도록 학습
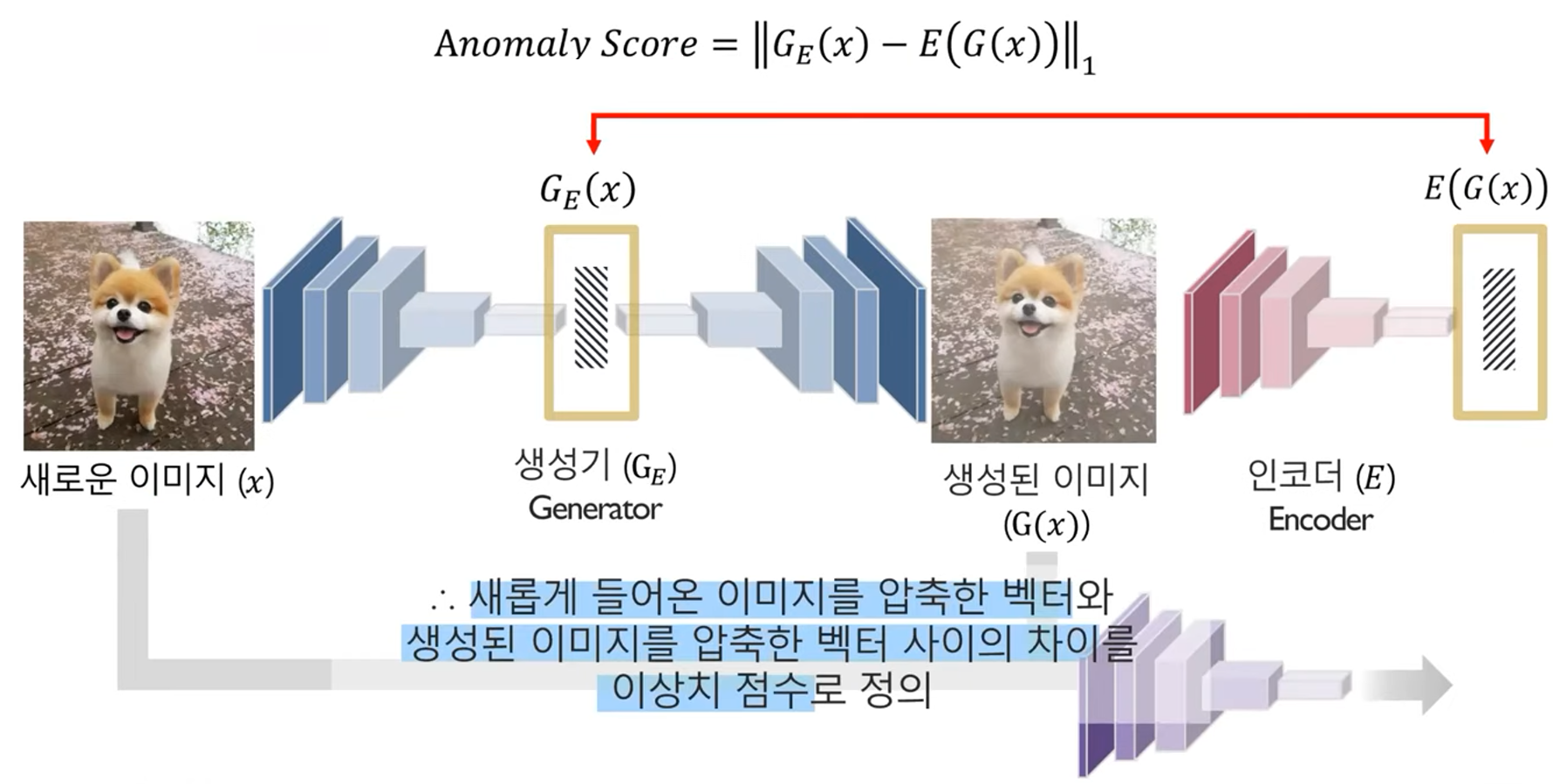
Anomaly Score: 이미지가 아닌 latent vector의 차이를 점수로 사용
(주의 - 두 이미지의 차이를 사용하는게 아님!)
'Learn > 머신러닝' 카테고리의 다른 글
선형 회귀 (Linear Regression) (0) 2022.10.09 정규화 모델 (Ridge, LASSO, Elastic Net) (0) 2022.09.03 [Anomaly Detection] SVM, SVDD (1) 2022.08.11 [Anomaly Detection] Isolation Forest (0) 2022.08.11 [Anomaly Detection] Local Outlier Factor (LOF) (0) 2022.08.10